
Devchat - 코드 중심 협업 채팅 서비스
프로젝트 기간 : 2025.05 ~ 2025.06 (2개월)
프로젝트 인원 : 4명
프로젝트 사용 기술 스택
- BE : Java, SpringBoot, SpringJPA, SpringSecurity
- FE : JavaScript, React
- DB : MySQL, Redis
- Infra : AWS EC2, Docker Compose, NGINX
- TestTool : JUnit, JMeter, Postman
- Monitoring : Prometheus, Grafana
Github 주소 : https://github.com/LimKangHyun/NBE5-7-2-Team08
배포 주소 : https://thedevchat.duckdns.org
프로젝트 설명
팀 프로젝트를 하다 보면 GitHub와 Slack을 동시에 쓰게 되는데, Slack에서는 코드 라인 단위 리뷰가 불편하고, 코드 하이라이팅도 제대로 지원되지 않아 답답할 때가 많았습니다.
Devchat은 이런 불편을 해결하기 위해 만든 플랫폼입니다. 깃허브 레포지토리 주소만 입력하면 알림을 받을 수 있고, 언어별 코드 하이라이팅을 지원해 코드 리뷰와 가벼운 코드 대화를 모두 편하게 진행할 수 있습니다.
즉, 공식적인 기록은 GitHub에서, 코드 중심 소통은 Devchat에서 진행하여 한 곳에서 협업 효율을 높일 수 있는 도구입니다.
+ 지금 보면 많이 부족한 부분도 보이고, 빈틈이 많이 보이는 프로젝트이지만, 그만큼 많이 배우고 성장할 수 있는 기회가 많았던 프로젝트였습니다...ㅎㅎ
DB 설계
Devchat은 메시지 수정·삭제 기능을 제공하며, 변경 사항이 모든 사용자에게 일관되게 반영되어야 했습니다. 트랜잭션과 정합성 보장이 필요했기 때문에 MySQL을 선택했습니다.
또한 메시지의 실제 삭제 대신 상태값(NORMAL / EDITED / DELETED)을 함께 관리하여 DELETED에 대해 소프트 딜리트를 적용해 변경 상태를 추적하고 데이터 무결성을 확보했습니다.
ERD
[ 초기 mvp의 ERD ]
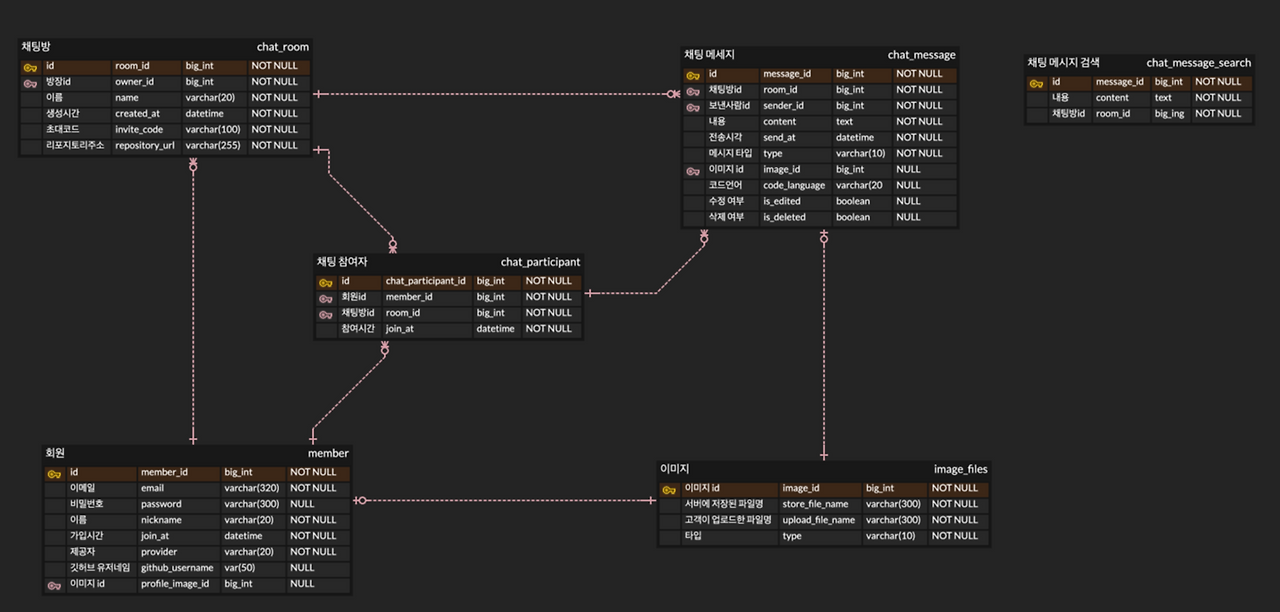
서비스의 초기 MVP ERD는 최소 기능 구현을 목표로 설계했습니다.
기본적으로 회원 – 채팅방 – 메시지 구조를 중심으로 했고, 메시지에 이미지를 첨부하거나 검색할 수 있도록 테이블을 분리했습니다.
또한, 채팅방 테이블에 GitHub 레포지토리 URL을 매핑하여, 각 채팅방에서 GitHub Webhook 알림을 받을 수 있도록 구성했습니다.
[ 최종 ERD ]
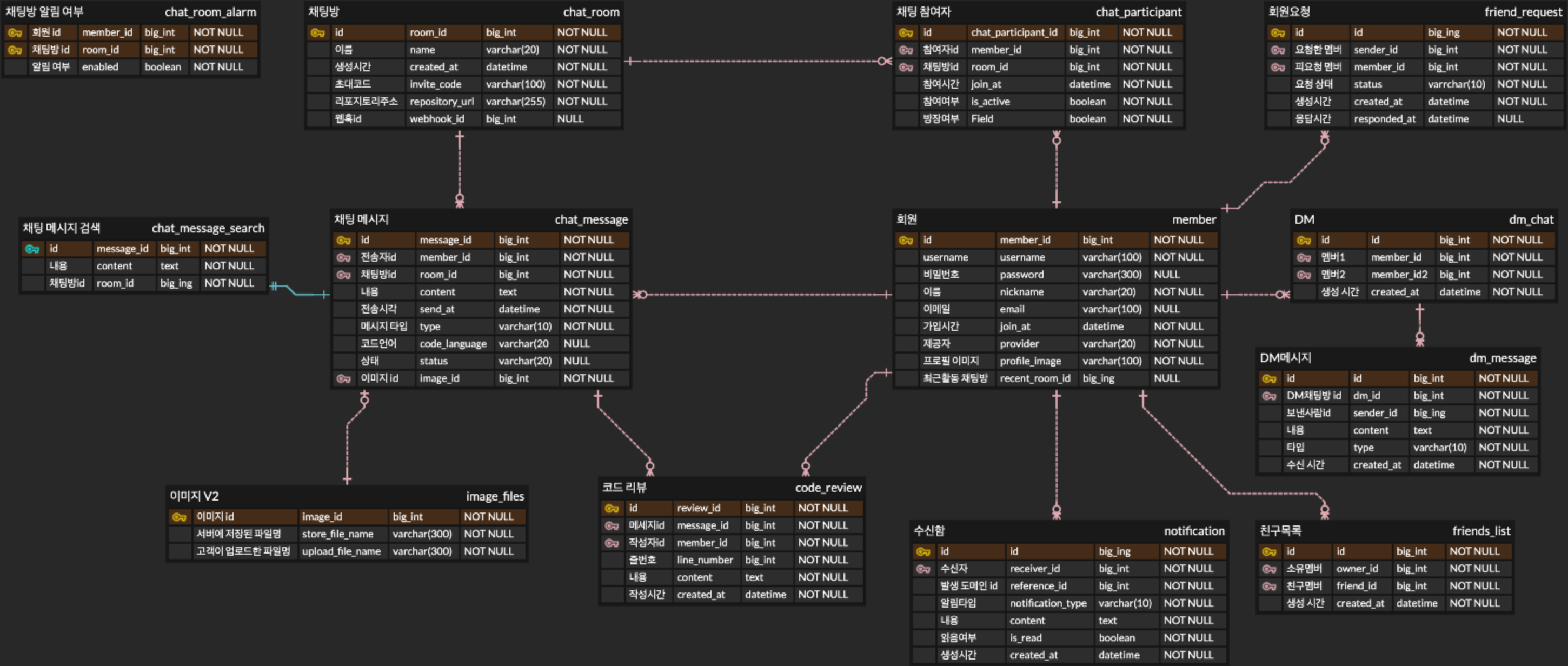
MVP에서 구현한 핵심 테이블 구조
이번 프로젝트 MVP에서는 회원, 채팅방, 메시지 관련 기능에 집중했습니다. 각 테이블의 역할은 아래와 같습니다.
1. 회원 관련 테이블
- member: 서비스의 기본 회원 정보 관리 (아이디, 닉네임, 이메일, 프로필 이미지 등)
2. 채팅방 관련 테이블
- chat_room: 채팅방 기본 정보 관리 (이름, 생성 시간, 초대 코드, GitHub 레포 URL 등)
- chat_participant: 채팅방 참여자 관리, 참여 시간과 방장 여부 포함
3. 메시지 관련 테이블
- chat_message: 발신자, 채팅방, 내용, 전송 시간 등 메시지 정보 관리
- chat_message_search: 검색용 메시지 테이블, ID와 내용 중심
- image_files: 메시지 첨부 이미지 관리
- code_review: 메시지 단위 코드 리뷰 관리, 작성자와 줄 번호 포함
트러블 슈팅 🚀
1. 채팅 메시지 조회 시, 추가 정렬 비용 및 성능 저하 문제
기존에는 message_id(PK) 단일 인덱스만 사용하고 있었습니다. 처음에는 큰 문제가 없어 보였지만, 실제 채팅 화면에서는 room_id로 필터링하고 message_id 기준 최신순으로 정렬하는 패턴이었기 때문에, 데이터가 많아지면 조회 속도가 느려지는 문제가 있었습니다.
그래서 커버링 인덱스를 도입하기까지의 과정을 정갈하게 적어보았습니다.
문제 해결 접근
1️⃣ PK 단일 인덱스로만 조회
처음에는 PK만으로 조회를 시도했습니다. 하지만 의도적으로 몇만 건에서 몇십만 건까지 메시지를 넣고 방 단위로 조회해보니, 조회 속도가 점점 느려지는 것을 확인할 수 있었습니다. 단일 PK 인덱스로는 room_id 필터와 최신순 정렬을 동시에 만족시키기 어려웠던 것이죠.
2️⃣ message_id 단일 인덱스 추가
다음으로 message_id 컬럼에 별도의 단일 인덱스를 추가했습니다. 하지만 결과는 크게 달라지지 않았습니다. DB는 단일 인덱스를 각각만 활용할 수 있기 때문에, 복합 조건을 동시에 만족시키지 못했고, 여전히 대량 데이터 조회 시 성능 병목이 발생했습니다.
3️⃣ 커버링 인덱스 도입
최종적으로 room_id + message_id DESC 형태의 커버링 인덱스를 적용했습니다.
- 이 인덱스는 방 단위 필터와 최신순 정렬을 동시에 처리할 수 있도록 구성되어, DB가 인덱스만 보고 바로 결과를 찾고 정렬할 수 있습니다.
- 테이블의 실제 데이터를 모두 읽지 않아도 되므로 디스크 I/O가 거의 발생하지 않고, 대량 데이터 환경에서도 조회 성능이 눈에 띄게 개선되었습니다.
이 인덱스를 적용함으로써, DB는 방별 데이터를 효율적으로 찾고 정렬할 수 있게 되었고, 실제 쿼리 성능도 눈에 띄게 개선되었습니다.
아래는 AWS EC2 배포 서버에서 동일한 환경 및 동일 데이터와 동일한 조회 쿼리를 기준으로 테스트하고,
EXPLAIN ANALYZE로 확인한 쿼리 실행 비용 / 그라파나로 모니터링한 TPS / 조회 API 평균 응답 시간입니다.

▼

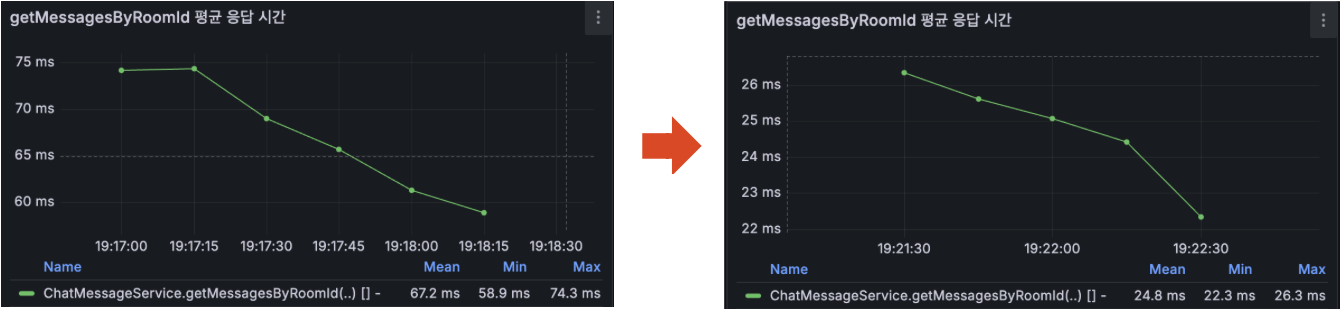
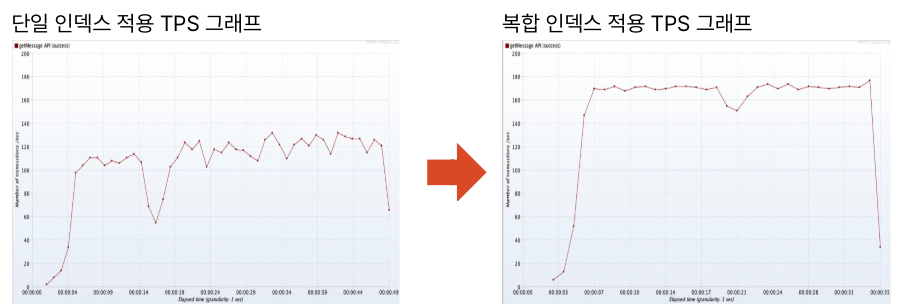
성능 개선 결과 정리(약 10만 건 기준):
- 쿼리 실행 비용: 10,615 → 2,871 (약 73% 감소)
- 채팅 조회 API 평균 응답시간: 67.2ms → 24.8ms (약 63% 감소)
- TPS: 106 → 155 (약 46% 증가)
고려한 트레이드오프
물론 쓰기 시 약간의 인덱스 유지 비용이 발생하지만,
조회 요청이 훨씬 많고 최신 메시지 조회 속도가 서비스 경험에서 중요하기 때문에 메시지 조회에 필요한 최소한의 칼럼만으로 복합인덱스를 구성한다면, 해당 트레이드오프를 감수할 수 있다고 판단하였습니다.
해당 트러블슈팅을 통해, 단순히 인덱스를 추가하는 것이 아니라 실제 서비스 조회 패턴을 이해하고, 그에 맞게 구조를 설계하는 것이 얼마나 중요한지 깨달았습니다.
직접 제가 만든 서비스에 메시지 데이터를 많이 집어넣어보고 경험해본 속도의 차이여서 그런지 성능 최적화는 스펙적인 수치 향상을 넘어 사용자 경험과 서비스 안정성에 직결된다는 점이 더 크게 와닿았던 것 같습니다.
2. 채팅방 입장 인원 폭증 시, 브로드캐스팅 지연 문제
부하 테스트를 진행하면서 채팅방에 한꺼번에 많은 사용자가 입장할 때,
입장 메시지 브로드캐스팅이 느려지는 걸 보고 처음에는 단순히 처리량이 많아서 발생하는 일반적인 지연이라고 생각했습니다.
하지만 테스트 중 서비스가 아예 뻗어버리는 상황까지 겪으면서, 문제가 단순한 부하 때문만은 아니지 않을까... 라는 생각에 코드부터 하나하나 살펴보았습니다.
코드를 찬찬히 살펴보던중 사용자가 채팅방에 입장하면 입장 정보를 테이블에 저장하고, 이벤트 리스너를 통해 메시지를 브로드캐스팅하는 것 까지 요청받은 스레드로, 동기 방식으로 하나의 트랜잭션 내에서 처리되고 있다는 것을 확인했습니다.
즉, 입장 메시지 브로드캐스팅 작업이 메인 API 응답 스레드 안에서 실행되어, 유저 응답 지연의 원인이 되고 있었습니다.
문제 해결 접근
- DB 저장과 브로드캐스트 작업 분리
- @TransactionalEventListener(phase = AFTER_COMMIT): DB 롤백을 고려해, 커밋 이후에만 이벤트 실행
- @Async: 브로드캐스트 작업을 별도 스레드에서 비동기 처리
- 커스텀 스레드 풀: 과도한 동시 요청으로 인한 스레드 낭비 방지, 풀 사이즈 제한 (corePool=5, maxPool=20)
(AWS 프리티어이지만 동기/비동기의 처리 구조의 차이를 명확히 보기위해 코어풀을 5로 두었습니다.)
이 구조를 적용한 이후, 메인 API 스레드는 입장 요청에 대한 응답 처리에만 집중하고 브로드캐스트 작업은 별도 스레드에서 수행되면서 입장 시 체감 지연이 크게 감소했습니다.
고려한 트레이드오프
- 비동기 처리로 인해 입장 메시지 브로드캐스트 순서가 완벽하게 입장 순서와 일치하지 않을 수 있음
- 브로드캐스트 실패 시 즉시 전달 보장이 어려움
- 그러나 모든 입장 메시지는 DB에 기록되므로, 사용자가 입장 메시지를 놓치더라도 이후 채팅 메시지 조회 API를 통해 확인 가능
(즉, 장기적 데이터 정합성은 유지됨)
하지만, 서비스를 운영하는 데 있어서, 데이터 정합성을 완벽하게 유지하고 수많은 트래픽 부하를 견뎌야하는 구조가 필요하기 때문에,
향후에는 메시지 큐(MQ)를 활용해 브로드캐스팅 순서와 신뢰성을 보다 완벽하게 보장하는 구조로 개선할 계획입니다.
3. 채팅 데이터양에 따른 검색 속도 저하 문제
부하 테스트를 진행하던 도중, 특정 키워드 패턴이 없는 상태에서 채팅 메시지 수가 증가할수록 검색 속도가 눈에 띄게 저하되는 현상을 확인했습니다.
채팅 메시지가 수만 건 수준일 때까지는 큰 문제가 없었지만, 10만 건에 가까워지자 검색 요청의 응답 시간이 체감될 정도로 느려지기 시작했습니다.
처음에는 단순히 데이터가 많아졌으니 느려지는 것이 당연하다고 생각했습니다.
채팅 검색 특성상 LIKE '%keyword%' 형태의 쿼리를 사용하여 구현했고, 이 방식은 B-Tree 인덱스를 제대로 활용하지 못하는 구조라는 점도 이미 알고 있었습니다.
일반적인 인덱스는 문자열의 앞부분부터 정렬된 상태로 저장되는데, '%keyword%'처럼 와일드카드가 앞에 붙는 경우, DB는 검색 시작 지점을 특정할 수 없어 인덱스를 타지 못하고 테이블(또는 인덱스) 전체를 스캔하게 됩니다.
즉,
- LIKE 'keyword%' → 인덱스 범위 스캔 가능
- LIKE '%keyword%' → 시작 지점을 알 수 없어 인덱스 미사용
채팅 메시지는 키워드가 문장 중간 어디에든 등장할 수 있기 때문에, 검색 정확도를 위해 어쩔 수 없이 '%keyword%' 형태를 사용할 수밖에 없었고, 그 결과 데이터가 많아질수록 검색 비용이 급격히 증가하는 구조였습니다.
문제 해결 접근 (시도 1)
LIKE 검색 한계를 인지한 상태에서, 문자열 전체를 토큰 단위로 관리하는 FULL TEXT INDEX를 적용해 검색 방식 자체를 개선해보고자 했습니다.
먼저 FULL TEXT INDEX를 사용한 검색 방식은, LIKE '%keyword%' 형태의 검색과 달리 문자열 전체를 선형 스캔하지 않고,
사전에 토큰화된 인덱스를 기반으로 검색 대상 레코드를 빠르게 좁힐 수 있다는 장점이 있습니다.
LIKE 검색은 와일드카드(%)가 문자열 앞에 포함되는 경우, B-Tree 인덱스를 활용할 수 없기 때문에 모든 row를 순차적으로 검사하는 구조가 됩니다.
따라서, 채팅 메시지처럼 데이터가 계속 누적되는 테이블에서는 데이터 양에 비례한 성능 저하로 이어진다는 것을 알게 되었습니다.
반면, FULL TEXT INDEX는
- 메시지 내용을 단어 단위로 분해하여 인덱싱하고
- 검색 시에도 해당 토큰을 기준으로 매칭되는 row만을 대상으로 처리하기 때문에
데이터 건수가 증가하더라도 검색 범위를 효과적으로 줄일 수 있을 것이라 기대했습니다.
특히 별도의 검색 서버(ElasticSearch 등)를 도입하지 않고도, RDBMS 수준(InnoDB)에서 검색 성능을 개선할 수 있다는 점에서
현재 서비스 규모와 운영 리소스에 적합한 선택이라고 판단해 FULL TEXT INDEX를 우선 적용했습니다.
적용 이후, 실제 쿼리 성능 개선 효과를 확인하기 위해
채팅 메시지 수를 단계적으로 증가시키며 LIKE 검색과 FULL TEXT INDEX 검색의 쿼리 실행 시간을 직접 비교 측정했습니다.
측정은 동일한 조건에서,
- 패턴이 없는 키워드 검색
- 정확한 비용 측정을 위해 매 실행마다 버퍼/프로시져 캐시 클린 후 실행
- 정렬 및 페이지네이션 로직을 제외한 순수 검색 쿼리만 실행하는 방식으로 진행했습니다.
-- %LIKE% 검색
SELECT id
FROM chat_message_search
WHERE room_id = :roomId
AND content LIKE CONCAT('%', :keyword, '%');
-- FULL TEXT INDEX 검색
SELECT id
FROM chat_message_search
WHERE room_id = :roomId
AND MATCH(content) AGAINST (:keyword IN NATURAL MODE);| LIKE 검색 | FULL TEXT INDEX 검색 | |
| 채팅 1만 건 | 112ms | 40ms |
| 채팅 5만 건 | 175ms | 44ms |
| 채팅 10만 건 | 179ms | 42ms |
그 결과, FULL TEXT INDEX를 적용한 쿼리는 LIKE 검색 대비 데이터 건수가 증가할수록 실행 시간이 안정적으로 유지되는 것을 확인할 수 있었고, 특히 5만~10만 건 이상의 데이터 구간에서는 체감될 정도의 성능 차이가 나타났습니다.
이 시점에서는,
ElasticSearch 같은 별도의 검색 서버를 도입하지 않고도 DB 레벨에서 충분한 성능 개선을 이룬 것처럼 보였습니다.
하지만 실제 서비스 API를 통해 검색을 반복 테스트해보니, 쿼리 성능 개선에 비해 전체 검색 응답 속도는 기대만큼 빨라지지 않았습니다.
쿼리 자체는 빨라졌는데, 실제 검색의 속도는 여전히 느렸고, 채팅의 양이 많아질 수록 오히려 더 지연되는 현상이 나타났습니다.
그래서 검색 성능이 단순히 검색 인덱스의 문제가 아니라 조회 이후의 처리 과정에 병목이 존재할 가능성을 의심하게 되었습니다.
그래서 쿼리 실행 계획과 실제 검색 API의 동작 흐름을 다시 살펴보며, OFFSET 기반 풀 쿼리를 기준으로 실행 계획을 분석한 결과, OFFSET 페이지네이션이 주요 성능 병목임을 확인했습니다.
OFFSET 방식은 내부적으로
- 조건에 맞는 전체 결과를 정렬한 뒤
- 앞의 N개 레코드를 모두 스캔하고 버린 후
- 그 다음 LIMIT 만큼 가져오는 방식입니다.
따라서, 페이지가 뒤로 갈 수록 앞의 레코드를 모두 스캔하는 비용이 증가하게 되어 FULL TEXT INDEX의 성능이 전혀 발휘되지 못했던 것입니다.
문제 해결 접근 (시도 2)
그래서 검색 API의 페이지네이션 방식을 OFFSET → 커서 기반 방식으로 변경했습니다.
커서 기반의 페이지네이션을 사용하게 된 근거는 아래와 같습니다.
- 이전 페이지의 마지막 ID를 기준으로 바로 다음 데이터를 조회 가능
- 불필요한 레코드 스캔 비용 제거
- 데이터 양에 상관없이 성능 유지 가능
이러한 판단은 쿼리 실행 계획 분석(EXPLAIN ANALYZE) 결과를 통해 명확해졌습니다.
OFFSET 기반 검색의 경우, 마지막 페이지에 가까워질수록 OFFSET + LIMIT 만큼의 결과를 정렬 대상으로 올린 뒤, 실제 반환하지 않을 다수의 레코드를 필터링하여 버리는 실행 경로를 확인할 수 있었습니다.(버리는 행까지 스캔 비용 추가)
반면 커서 기반 검색은 id < lastMessageId 조건을 통해 정렬 대상 자체를 선제적으로 줄이며, 정렬 비용과 스캔 범위를 최소화하는 구조임을 확인했습니다.
다만, 커서 기반 페이지네이션은 마지막 ID만을 기준으로 조회하기 때문에 다음 페이지로의 이동은 쉽지만, 이전 페이지로 이동하려면 이전 커서 값을 알고 있어야 한다는 한계가 있었습니다.
이를 보완하기 위해 프론트엔드에서 메모리에서 커서 스택을 관리하는 방식을 적용했습니다. 각 페이지 조회 시 사용한 커서를 저장하고, 다음 페이지 이동 시 push, 이전 페이지 이동 시 pop하여 이전 커서를 재사용하는 구조입니다.
이 방식으로 서버는 상태를 유지하지 않으면서도 사용자는 이전 페이지를 자연스럽게 이동할 수 있었고, OFFSET 기반 페이지네이션과 유사한 사용자 경험을 제공할 수 있었습니다.
AWS EC2 배포 서버에서, 패턴 없는 50만 건의 채팅 데이터를 대상으로 스레드 1개로 총 20건의 검색 API 요청을 순차적으로 보내 테스트했으며, EXPLAIN ANALYZE로 확인한 스캔 ROW 개수 / 그라파나로 조회 API 평균 응답 시간을 모니터링하여 비교했습니다.
측정은 검색결과의 첫 번째 페이지와 마지막 페이지 기준으로 오프셋 기반 검색, 커서 기반 검색을 수행했고,
단일 스레드/동일 데이터셋/동일 요청 수 환경에서의 평균 응답 시간 비교는 두 페이징 방식의 상대적 성능 차이를 판단하기에 충분하다고 보았습니다.

▼

필터링 row 수 비교
- OFFSET 방식: 49,310건 -> 검색 결과와 동일, Limit개수를 제외한 모든 스캔된 행이 버려짐
- CURSOR 방식: 10건 -> Limit와 동일, 불필요한 스캔 없음
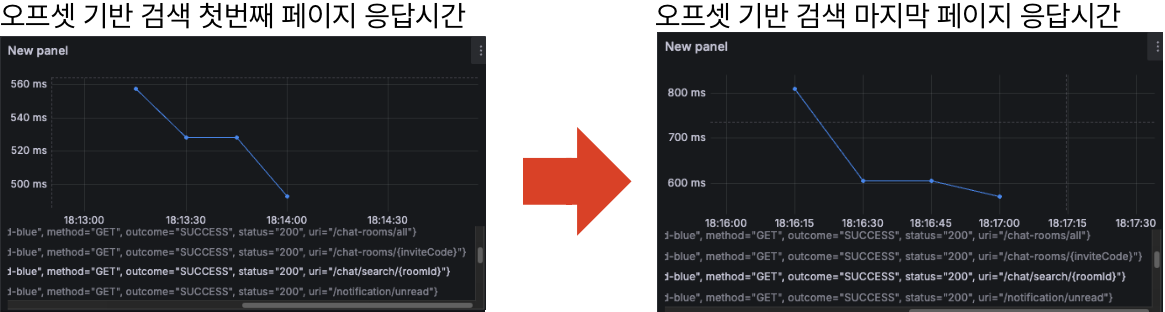
첫 번째 페이지에 비해 마지막 페이지의 검색 API 응답속도가 더 느림

첫 번째 페이지와 마지막 페이지의 검색 API 응답속도가 거의 동일
성능 개선 결과 정리(약 50만 건 기준):
- 쿼리 실행 비용: 10,615 → 2,871 (약 73% 감소)
- 채팅 조회 API 평균 응답시간: 67.2ms → 24.8ms (약 63% 감소)
- TPS: 106 → 155 (약 46% 증가)
추가로, 첫 번째 페이지를 조회하는 경우에도 OFFSET 방식과 CURSOR 방식 간의 성능 차이가 관찰되었습니다.
OFFSET 값이 0이기 때문에 두 방식의 성능이 유사할 것이라 예상할 수 있지만, 실제로는 커서 기반 방식이 더 빠른 응답 시간을 보였습니다.
이는 OFFSET 방식이 첫 페이지 조회 시에도 전체 결과 수 계산을 위한 COUNT 쿼리와 Page 객체 생성을 위한 부가적인 처리 비용을 함께 수행하는 반면, 커서 기반 방식은 Slice 기반 조회를 통해 필요한 데이터와 다음 페이지 여부만 확인하기 때문입니다.
즉, 첫 페이지에서도 커서 기반 방식은 쿼리 자체뿐 아니라 애플리케이션 레벨의 불필요한 페이징 비용을 줄일 수 있었고,
이 차이가 응답 시간의 차이로 이어졌다고 판단했습니다.
고려한 트레이드오프
커서 기반 페이지네이션은 임의 페이지(특정 번호 페이지)로의 점프가 어렵다는 제약이 있지만, 채팅 검색 특성상 대부분 최근 메시지부터 순차적으로 탐색한다는 점을 고려하면 실제 서비스에서는 충분히 감수 가능한 트레이드오프라고 판단했습니다.
그 결과, OFFSET 방식에서 발생하던 성능 저하를 제거하고, 데이터 양에 관계없이 안정적인 검색 성능을 확보할 수 있었습니다.
다만, 현재 채팅 검색 로직은 모든 요청이 바로 DB로 쏴지는 구조이기 때문에, 추후에는 MQ와 Redis를 활용한 비동기 인덱싱 구조로 개선이 필요할 것 같습니다.
메시지 큐가 적용된다면 새로운 메시지 인덱싱을 비동기적으로 처리하여 검색 시 DB에 직접 접근하는 부담을 줄일 수 있으며, 실시간성이 중요한 채팅 환경에서도 안정적이고 빠른 검색 성능을 유지할 수 있습니다.
향후에는, 커서 기반 페이지네이션과 비동기 인덱싱을 결합하여, 대규모 메시지 환경에서도 성능 저하를 최소화할 수 있는 구조로 구현할 계획입니다.
Keep / Problem / Try
그래서 이번 프로젝트를 진행하면서 느낀 점은, 작은 부분 하나라도 처음부터 꼼꼼하게 설계하고 테스트하는 습관이 중요하다는 것입니다.
특히 데이터 구조, 검색 로직, 페이지네이션 방식처럼 성능에 직접적인 영향을 주는 부분은, 나중에 기능이 많아지고 데이터가 쌓였을 때 문제를 미리 방지할 수 있는 기반이 된다고 생각합니다.
완벽하지 않아도 괜찮지만, 초기 설계 단계에서 충분히 고민하고 최적화 포인트를 반영해 두면, 실제 서비스 환경에서 안정성과 확장성을 확보하는 데 큰 도움이 된다는 것을 느꼈습니다.
Keep
다음 프로젝트에도 계속 이어가고 싶은 부분
- 팀원 간 상세한 코드 리뷰 문화 유지
- 단순 동작 확인이 아닌 설계 의도, 트레이드오프, 개선 포인트 중심으로 리뷰
- 기술 선택 시 멘토 및 팀 내 합의를 통한 의사결정 프로세스
- 유행 기술이 아닌, 문제 해결에 꼭 필요한 기술만 선택
- 불필요한 복잡도를 줄이며 오버엔지니어링을 지양
- 데일리 스크럼을 통한 커뮤니케이션 강화
- 매일 진행 상황과 이슈를 공유하며 팀 내 신뢰 형성
- 스크럼을 통해 하루 단위 목표를 유동적으로 조정하여 애자일한 개발 프로세스를 유지할 수 있었음
Problem
개선이 필요한 부분
- 이미지 업로드 기능의 한계
- 파일 용량 제한, 업로드 실패 시 사용자 피드백 부족
- 프론트엔드 성능 이슈
- 채팅 조회는 무한 스크롤 방식으로 이루어졌으나, 이미 조회된 모든 채팅 메시지가 DOM에 누적되어 유지되면서 대화량이 많아질수록 렌더링 성능 저하가 발생함
Try
PROBLEM에 대한 해결책, 다음 프로젝트에 바로 적용할 수 있는 것
- 이미지 업로드 개선
- Presigned URL 또는 업로드 서버 분리 방식 검토
- 업로드 상태 및 실패에 대한 명확한 UX 제공
- 프론트엔드 성능 최적화
- 가상 스크롤(virtualized list)을 통해 DOM 렌더링 최소화
- 채팅 조회 성능 개선
- 대화량이 많은 채팅방에서 빈번한 재진입 시 발생하는 조회 지연과 DB 부하를 개선하기 위해 Redis 기반 캐시 구조를 설계
- Redis 기반 캐시를 도입하여 채팅방별 최근 메시지 N개 조회 성능 개선
- TTL 기반 캐시 만료 정책과 메시지 수정/삭제 이벤트에 따른 선택적 캐시 무효화 전략 설계
- 캐시는 조회 가속 용도로만 사용하고, 데이터 정합성은 RDBMS를 기준으로 유지